🎣 pFisher Catch #2

Siedzę przy kawie, scrolluję Internety i myślę sobie: jak to możliwe, że cały internet stoi na jednej nodze, wszyscy o tym wiedzą, a nikt nic z tym nie robi?
Miniony tydzień pokazał nam kilka rzeczy. Po pierwsze: że jeśli jesteś CISO-em podczas supply chain attack, to lepiej miej dobrego kardiologa. Po drugie: że "globalne usługi" AWS są tak samo globalne jak "demokratyczna" republika. Czyli wcale. Po trzecie: że Northern Virginia to nie tylko stolica Ameryki, ale i całego internetu. Co może pójść nie tak, gdy ćwierć światowego ruchu przechodzi przez obszar dwóch Warszaw?
A przy okazji dowiedzieliśmy się, że NSO Group (ta od Pegasusa) - firma z amerykańskiej czarnej listy za szpiegowanie amerykańskich urzędników - została kupiona przez... amerykańskich inwestorów. Bo przecież najlepszy sposób na walkę z inwigilacją to... zainwestować w nią?
I jeszcze ten smaczek: Europol chwali się rozbiciem farmy SIM, która działała 7 lat. Przez siedem. Lat. Nikt nie zauważył 40 000 aktywnych kart w jednym miejscu. Nikt. No może wszyscy, ale udawali, że nie widzą.
A na koniec, bonusowo: moja interpretacja tego, co naprawdę się zje...psuło w AWS. Bo oficjalny post mortem to jedno, ale jak to wygląda od strony kogoś, kto widział tę awarię przez 16 godzin na produkcji - to zupełnie inna historia.
Ten tydzień to lekcja tego, że w technologii nie ma przypadków. Jest tylko to, co widzimy i to, co udajemy że nie widzimy.
🐟 Złowiłem w tym tygodniu

🎯 Tim Brown: Collateral Damage supply chain attack, który prawie kogoś zabił
Gdy czujesz ten cierpko-słodki smak stresu w ustach, a serce bije jak młotem - to być może jesteś Tim Brown. Szefem cyberbezpieczeństwa w SolarWinds, którego firma została użyta przez rosyjski wywiad do ataku na amerykański rząd. I niemal go to zabiło.
12 grudnia 2020 roku. Kevin Mandia dzwoni do niego z informacją, że SolarWinds "wysłało skażony kod" do swojego oprogramowania Orion.
18 000 klientów pobrało backdoora umieszczonego przez rosyjską SVR. Ministerstwo skarbu USA, departament handlu, tysiące firm - wszystko w rękach hakerów.
Brown schudł 9 kilogramów w 20 dni.
"Świat płonął", mówi. Wszyscy chcieli gadać, nie pisać. CNN, 60 Minutes, armia amerykańska - wszyscy dzwonili do niego osobiście. Bo gdy coś się sypie, ludzie chcą usłyszeć ton głosu, nie przeczytać komunikat prasowy.
Supply chain to piekło. Tylko ostatnie - Salesloft Drift - chatbot AI zintegrowanego z Salesforce - kradzież z 40 organizacji. F5 BIG-IP miał przez rok chińskich hakerów w kodzie źródłowym.
SolarWinds nie był celem - był drogą do celu. Rosjanie nie chcieli ukraść ich kodu ani zniszczyć firmy. Chcieli dostać się do amerykańskich agencji rządowych. I wykorzystali do tego zaufanie, jakim cieszy się ich firma.
Czy rozumiemy, jak często jesteśmy "drogą do celu"?
Twoja firma może nie być interesująca dla hakerów, ale jeśli obsługujesz kogoś, kto jest - stajesz się bramą. Każdy dostawca SaaS, każda integracja, każdy vendor w supply chain może być następnym SolarWinds.
Brown przez trzy lata walczył z SEC, które oskarżyło go osobiscie o wprowadzanie w błąd inwestorów. Stres narastał tak długo, że... miał zawał serca w Zurichu. Nie rozpoznał objawów. Myślał, że radzi sobie ze stresem.
"To się stało na mojej zmianie", mówi o ataku. Został w firmie przez cały proces. Tim Brown, był tylko... Collateral Damage. Uparty? Może. Ale rozumiem. Czasem trzeba doprowadzić sprawę do końca, nawet jeśli cię to niszczy.
Firmy technologiczne traktują cyberbezpieczeństwo jak koszt, nie jak inwestycję. "Nothing happens until something happens". A potem jest już za późno na wszystko oprócz zarządzania kryzysem.
Brown zaleca teraz firmom po incydentach zatrudnianie psychiatrów dla zespołów. Bo to nie jest tylko kwestia technologii - to kwestia ludzi, którzy muszą funkcjonować pod presją świata, który nagle płonie.
Czy naprawdę musimy czekać na nasz własny "12 grudnia", żeby zrozumieć, że cyberbezpieczeństwo to nie tylko technologia, ale też zdrowie psychiczne ludzi, którzy ją obsługują?
Cały wywiad: https://archive.is/2daSa
🎯 O poniedziałkowej awarii AWS: gdy fundament runął o 7:26
O poniedziałkowej awarii AWS napisano już tak wiele i tak źle, że szkoda więcej czasu. Ale patrzyłem na nią przez 16 godzin, doświadczając na produkcji wszystkich możliwych "hickupów" - i widzę, żę pycha kroczy przed upadkiem.
AWS był tak pewny swojego DynamoDB, że obiecywał 99.999% uptime dla Global Tables. Tak pewny, że w dokumentacji pisał: "opieraj wszystkie swoje usługi na DynamoDB, to fundament wszystkich naszych wewnętrznych usług".
A potem ten fundament runął o 7:26 czasu europejskiego i pociągnął za sobą pół internetu.
US-EAST-1 to nie jest "zwykły region". To serce AWS - najstarszy, najtańszy, pierwszy dostający nowe funkcje. Tu mieszkają kontrole globalnych usług: Route 53, CloudFront, Organizations. Jeśli wdrożyłeś najlepsze praktyki AWS i używałeś multi-region z Organizations - wczoraj nie mogłeś się nawet zalogować do konsoli.
Obserwowałem przez te 16 godzin dwie awarie naraz. Pierwsza - DynamoDB padło z powodu DNS. Druga - okazało się, że "globalne usługi" wcale nie są globalne, tylko siedzą w jednym regionie. AWS sprzedawał nam "cloud resilience" przez lata, a sam postawił wszystko na jednej nodze.
To że awaria zaczęła się od DNS - tego samego DNS, który miał być "telefonem internetowym". To zawsze przez DNS, prawda?
Czytałem komentarze: "ale mamy multi-cloud!", "trzeba było używać backup regionów!". Bzdura. Gdy pada us-east-1, pada control plane większej części AWS. Nie pomoże ci drugi region, jeśli Twoja automatyzacja leży i nie możesz się zalogować do zarządzania nim.
Po 16 godzinach obserwacji jedna rzecz jest pewna: nie ma "bulletproof cloud". Jest tylko marketing, który każe nam uwierzyć, że oddając kontrolę gigantom techowym, zyskujemy bezpieczeństwo.
A praktyczny koszt? W USA: United Airlines, Delta opóźniały samoloty, kierowcy Amazon Flex zostali odesłani do domu bez płatności. W Europie? HMRC (urząd podatkowy UK) padł całkowicie. Brytyjskie banki Lloyds, Halifax, Bank of Scotland przestały obsługiwać klientów. Operatorzy Vodafone, EE, BT w UK oraz SFR i Free we Francji mieli problemy. Smart gniazdka nie działały. Roboty Roomba nie wyjechały… a i nie mogłeś też znaleźć dupy na Tinderze.
Nawet Signal - komunikator któremu przestał ufać sam Elon Musk ("I don't trust Signal anymore") - leżał jak reszta.
To nie była awaria "tylko" Snapchata czy Fortnite. To była awaria podstawowej infrastruktury, od której zależy codzienne funkcjonowanie milionów ludzi.
Pozwoliliśmy jednemu dostawcy zostać krytyczną infrastrukturą dla połowy internetu i nadal udajemy, że to "resilient architecture"?
Więcej monitoringu i więcej redundancji nie rozwiąże problemu systemów, które z założenia są zbyt duże, żeby bezpiecznie upaść?

🎯 NSO Group: zakaz exploitów, który nikogo nie powstrzyma
Może zakażemy exploitów i ich nie będzie? 🤔 NSO Group właśnie dostało permanentny zakaz wykorzystywania WhatsApp-a. Plus 167 mln $ odszkodowania za zhakowanie 1400 użytkowników. Problem rozwiązany?
Nie za bardzo.
W 2019 roku wyszło na jaw, że izraelska firma sprzedająca Pegasusa wykorzystała lukę w WhatsApp-ie do masowej inwigilacji dziennikarzy, aktywistów i dyplomatów. Sześć lat procesów, miliony wydane na prawników, setki stron dokumentów. I co dostaliśmy?
Zakaz dla jednej firmy, exploitowania jednej aplikacji...
I na pewno się zastosują.
Na pewno. Prawda?
Tymczasem Pegasus nadal działa. NSO znajdzie inne sposoby na infiltrację telefonów - "zero-click attacks", które nie wymagają nawet kliknięcia przez ofiarę.
A sama firma? Właśnie została sprzedana (ponownie) amerykańskim inwestorom za "dziesiątki mln $". Firma, która była na amerykańskiej czarnej liście za szpiegowanie amerykańskich urzędników, teraz ma amerykańskich właścicieli.
John Scott-Railton z The Citizen Lab: "NSO intensywnie próbowało wejść na rynek USA i sprzedawać swój produkt amerykańskiej policji. Ta technologia dyktatorska nie powinna być nawet blisko Amerykanów".
W Polsce już wiemy, jak to wygląda w praktyce.
Pegasus był używany przez CBA w latach 2015-2023 do inwigilacji polityków opozycji.
Meta świętuje "historyczne zwycięstwo". Mark Zuckerberg może się teraz chwalić, że "walczy z nielegalnym oprogramowaniem szpiegowskim". Ale prawda jest taka, że to przede wszystkim PR. WhatsApp ma ponad 3 miliardy użytkowników - to zawsze będzie kuszące.
NSO nie jest jedyną firmą produkującą spyware. Candiru, Cellebrite, Intellexa, Cytrox czy... Positive Technologies - całe zoo firm oferujących "rozwiązania do nadzoru" rządom na całym świecie. Zakaz dla NSO to jak zamknięcie jednego dealera w dzielnicy pełnej handlarzy.
Sędzia Hamilton zmniejszyła pierwotną karę 167 milionów dolarów do zaledwie 4 milionów, stwierdzając że zachowanie NSO nie było "szczególnie rażące".
NSO Group będzie prawdopodobnie odwoływać się od tego wyroku przez kolejne lata. Za pieniądze amerykańskich inwestorów, którzy kupili firmę mimo że była na czarnej liście. Kapitalizm w najczystszej postaci - nawet inwigilacja się opłaca.
Może zamiast zakazywać exploitów - nałożymy na nie cła? I będzie jeszcze na plus? A nie, bo to chyba jak czerpanie korzyści z działalności przestępczej...
Oh wait...

🎯 Operacja SIMCARTEL: 7 lat głośnej ciszy operatorów
Europol chwali się "największym sukcesem w walce z cyberprzestępczością". Operacja SIMCARTEL. Jednostka antyterrorystyczna OMEGA wyważa drzwi w Rydze. 7 aresztowanych. 40 000 kart SIM w 1200 urządzeniach. 49 milionów fałszywych kont.
Tylko... czemu musieli wyważać drzwi, żeby odkryć coś, co każdy operator telekomunikacyjny widzi w swoich dashboardach? 🤔
Mam zadanie dla Was.
Wyobraźcie sobie Rygę. 600k mieszkańców.
Wyobraźcie sobie 40 000 aktywnych kart SIM w jednym miejscu. Zalogowane na tych samych stacjach (BTS). Przez 7 lat. 1200 urządzeń SIM box.
Pytanie pierwsze: Co widzi operator sieci w logach, gdy setki kart loguje się z DOKŁADNIE tego samego miejsca, używając tych samych numerów IMEI urządzeń?
Ale jest lepiej. Te karty się zmieniają co chwilę - dzisiaj jedna SIM, jutro druga, pojutrze trzecia. Ten sam telefon (IMEI), tylko karty rotują. I to nie są łotewskie numery.
Na zdjęciach z akcji widać na przykład karty: Lycamobile (Dania), Lebara (NL), Primetel (Cypr), Haloo (Finlandia), (UK/DE)
Pytanie drugie: Kto zarejestrował te karty? Czyim nazwiskiem? W krajach, gdzie każda SIM wymaga KYC?
Te same urządzenia (IMEI), te same lokalizacje (BTS), tylko SIM się zmieniają. Przez 7 lat wygenerowały 49 mln kont. To 19 000 nowych kont DZIENNIE. SMS-y weryfikacyjne 24/7. Z Rygi.
Pytanie trzecie: Ile czasu potrzebuje system monitoringu operatora, żeby wykryć taki wzorzec? Godzinę? Dzień?
Europol pisze: "hundreds of thousands of further SIM cards seized". To było 40 000 AKTYWNYCH w danym momencie plus setki tysięcy w rezerwie.
Każdy operator wie, gdzie ma SIM farmy. KAŻDY. To nie jest coś, co trzeba "odkrywać" z jednostką antyterrorystyczną. To jest widoczne w basic network monitoring.
Pytanie czwarte: Kto im sprzedał setki tysięcy kart z krajów wymagających KYC? Czyimi danymi osobowymi były rejestrowane?
Gogetsms[.]com i apisim[.]com działały publicznie. Profesjonalna strona. Ceny. Support. API. Przez lata. I jeszcze jeden smaczek: Europol chwali się zamknięciem "crime-as-a-service", nie wspominając, że tymczasowe numery SMS używają też zwykli ludzie dla prywatności.
Czy teraz każdy serwis oferujący tymczasowe numery staje się podejrzany? Gdzie kończy się ochrona prywatności, a zaczyna "umożliwianie przestępstw"?
Pytanie piąte: Jak długo minęło, zanim ktoś pomyślał "hm, może to sprawdzimy"?
Lycamobile, Lebara, O2 - to duzi gracze telco z fraud detection i obowiązkiem raportowania do regulatorów.
Pytanie szóste: Jak wyjaśnić regulatorowi w Danii, że kilka tysięcy waszych kart przez lata wysyła SMS-y z tego samego miejsca w Rydze, ciągle zmieniając się w tych samych urządzeniach?
Europol pisze: "technically highly sophisticated".
To nie jest wyrafinowane. To jest GŁOŚNE.
Jedyne, co było wyrafinowane, to liczba lat, przez które wszyscy udawali, że tego nie widzą.
Może ktoś z telco, fraud detection wyjaśni mi - co mi umyka?
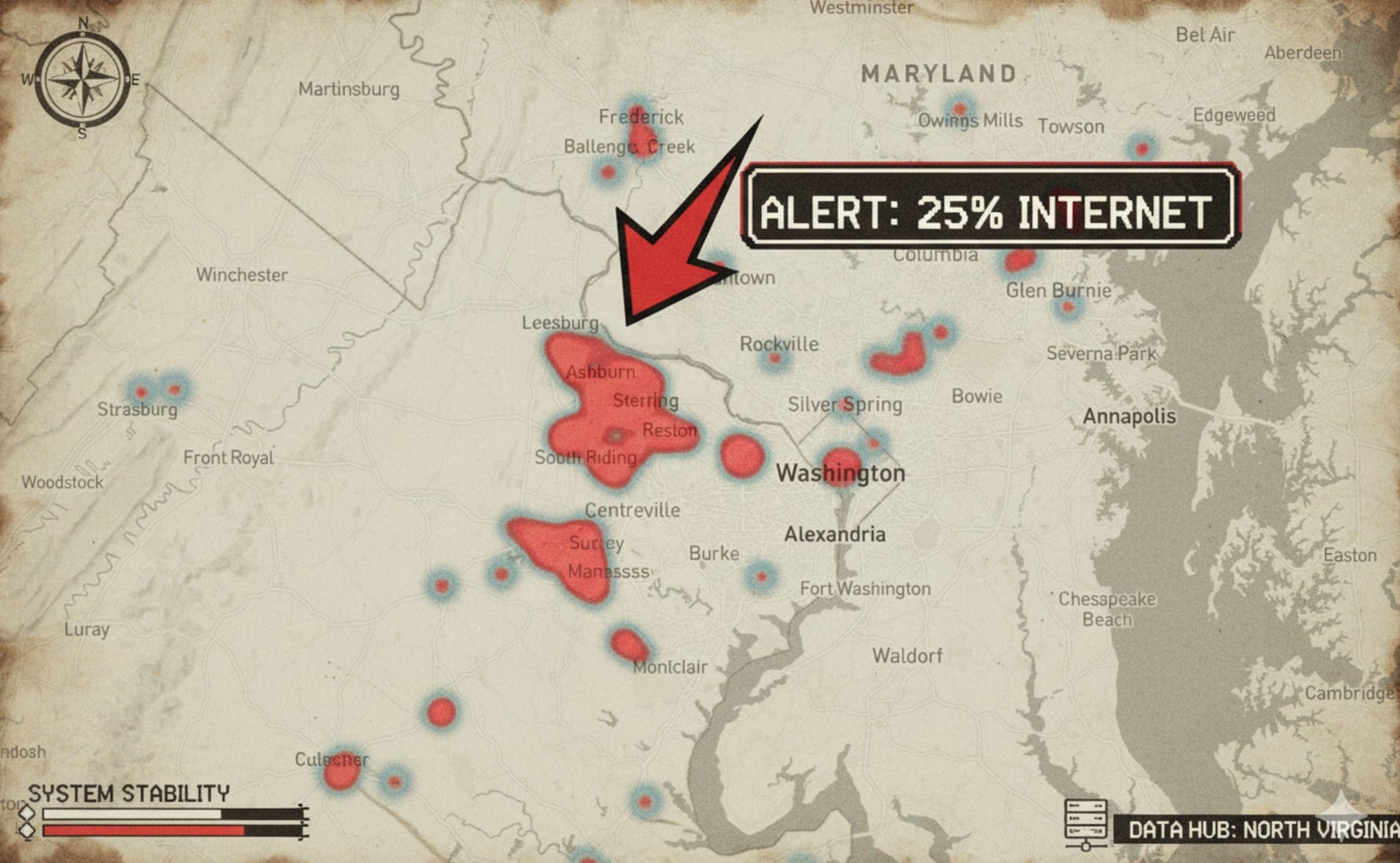
🎯 Northern Virginia: stolica internetu, którą nikt nie planował
Wyobraźcie sobie obszar 176 470 boisk piłkarskich. Około 1200 km². Albo, jeśli wolicie: dwóch Warszaw. Przez ten obszar przechodzi około 25% światowego ruchu internetowego, a przetwarzane jest dużo więcej. Wygląda jak jeden wielki pojedynczy punkt awarii?
Northern Virginia. Ashburn. Data Center Alley. Około 35 km x 35 km koncentracji.
Scrollujesz Instagram? Meta jest tam. Wysyłasz maila przez Gmail? Google tam. Oglądasz Netflixa? Tam. Zakupy na Amazonie? Tam. Slack w pracy? Tam. Roblox? Tam. OpenAI trenuje swoje modele? Zgadliście – Azure ma tam ogromne regiony.
MS, Apple, Meta, Amazon, Google – wszyscy mają tam swoje centra. I nie chodzi tylko o to, że oni tam są. Chodzi o to, że wszyscy TAM są. W tym samym miejscu.
W całej Wirginii jest około 655 DC. To niewiele mniej niż w DE (529) i NL (298) razem wziętych – krajach, które uchodzą za zagłębie internetu EU. Amsterdam – europejski hub – ma około 93 centra danych. (dane z datacentermap)
Historia? ARPANET – projekt Pentagonu z Arlington. MAE-East – pierwszy punkt wymiany internetowej na wschodnim wybrzeżu. Potem Equinix w latach 90, AOL, Yahoo!, AT&T. I zaczęło się. Nikt nie planował, że to będzie "stolica internetu" (a jednak nie Warszawa!). Po prostu tak się stało, bo "tu już jest najlepsza infrastruktura" i "wszyscy już tutaj są".
Ale co się stanie, gdy ten obszar padnie? Przy ostatniej awarii AWS kto padł? Lista jest długa. Brytyjskie banki też padły. Klienci odcięci od kont. W UK. Bo serwery w Wirginii przestały działać. Rządy europejskie krzyczą o "cyfrowej suwerenności", podczas gdy ich własne urzędy hostują się na us-east. 90% Fortune 100 używa AWS. W Finlandii 77% instytucji publicznych używa Microsoft – który hostuje się gdzie? A awarie już były. I będą.
I za każdym razem ten sam region: us-east. Northern Virginia.
Dlaczego wszyscy tam są? Bo tu jest najtańsza energia i inni też są. Bo Virginia daje ulgi podatkowe.
Dominion Energy – główny dostawca energii w regionie – przyznał publicznie: "nie możemy dostarczyć tyle energii, ile potrzebują nowe DC". Mieszkańcy Loudoun County protestują przeciwko kolejnym DC – hałas, utrata przestrzeni, obciążenie sieci. Ale budowa trwa. Każdego dnia.
Gdyby ten obszar przestał działać na dłużej - czy pozostałe 75% "niezależnego" internetu sobie poradzi? Wątpię. Wystarczy przypomnieć cięcia światłowodów w Morzu Czerwonym i Bałtyckim.
Bo to nie jest tylko kwestia infrastruktury. To kwestia zależności.
Zastanawiam się: czy świadomie podjęliśmy decyzję o koncentracji ćwiartki globalnego internetu na obszarze dwóch Warszaw? Czy po prostu tak się stało, krok po kroku, a teraz jest za późno, żeby to zmienić?
Może nie powinniśmy celebrować, że "Ashburn to stolica internetu". Może powinniśmy zacząć się martwić, co się stanie, gdy ta stolica przestanie działać.
Poscrolujcie sobie: https://www.datacentermap.com/content/nova/

🎯 BONUS: Moja interpretacja AWS post mortem
Race condition, które nie powinno się wydarzyć. Albo dokładnie: co się musiało spierdolić, żeby się zjebało.
Czytałem ten post mortem AWS trzy razy. Za każdym razem ten sam wniosek: to nie jest historia o jednym błędzie. To historia o architekturze, która działa dopóki nie działa.
DNS Planner i DNS Enactor - teoria vs. praktyka
AWS zarządza setkami tysięcy rekordów DNS dla DynamoDB w każdym regionie. System podzielony na dwa komponenty "dla dostępności":
- DNS Planner - monitoruje health load balancerów, co jakiś czas generuje nowy "plan DNS" (zestaw load balancerów + wagi dla każdego endpointu)
- DNS Enactor - wdraża te plany przez Route53. Działa redundantnie w trzech AZ, każda instancja całkowicie niezależnie.
Kluczowy mechanizm bezpieczeństwa? Transakcje Route53 zapewniają atomowość - nawet gdy kilka Enactorów próbuje zaktualizować ten sam endpoint, wygrywa tylko jeden. Plus: każdy Enactor przed rozpoczęciem aplikowania planu sprawdza jednorazowo, czy jego plan jest nowszy niż aktualnie wdrożony.
Brzmi solidnie, prawda?
Timing is everything - czyli jak skopać wszystko w trzech prostych krokach
Wszystko zaczyna się niewinnie. Jeden z Enactorów podnosi plan i zaczyna go wdrażać. Przechodzi przez listę endpointów, aplikuje zmiany. Standardowa robota.
Ale nagle - opóźnienia. Próbuje zaktualizować endpoint, blokuje go inny Enactor. Retry. Kolejny endpoint - znowu blokada. Retry. Ten proces, który normalnie zajmuje sekundy, ciągnie się i ciągnie.
W międzyczasie świat się kręci dalej:
- DNS Planner produkuje kolejne generacje planów (jak powinien)
- Drugi Enactor podnosi jeden z tych najnowszych planów
- I błyskawicznie przechodzi przez wszystkie endpointy - zero opóźnień, czysta robota
I tu zaczyna się dramat:
- Drugi Enactor kończy swoją robotę → uruchamia proces czyszczenia starych planów
- Proces czyszczenia identyfikuje plany "znacznie starsze" niż ten, który właśnie wdrożył → kasuje je
- Pierwszy Enactor (ten powolny) w końcu dociera do regionalnego endpointu DynamoDB
- Sprawdzenie "czy mój plan jest nowszy"? Tak, bo to sprawdzenie było NA POCZĄTKU procesu, kilka minut temu
- Aplikuje swój stary plan → nadpisuje nowy plan, który właśnie wdrożył drugi Enactor
- Proces czyszczenia drugiego Enactora dociera do tego planu i go usuwa, bo "za stary"
Ale to był aktywny plan. Dla regionalnego endpointu DynamoDB.
Route53 wykonał delete operacji. Wszystkie IP adresy endpointu dynamodb.us-east-1.amazonaws.com zniknęły. Pusty rekord DNS.
System w niespójnym stanie - kolejne próby aktualizacji przez innych Enactorów failują, bo aktywny plan nie istnieje. Wymaga ręcznej interwencji.
7:48 UTC - wszystko leci
Każdy, kto próbuje się połączyć z DynamoDB przez publiczny endpoint, dostaje DNS resolution failure (ja też!)
Klienci? Tak. Wewnętrzne serwisy AWS? Też.
Global Tables? Przestały się replikować między regionami - us-east-1 był odcięty.
Multi-region deployment z AWS Organizations? Nie możesz się zalogować do konsoli (ja też!), bo Organizations siedzi... w us-east-1.
8:38 UTC - inżynierowie AWS identyfikują problem
DNS w DynamoDB. Ale nie mogą go naprawić automatycznie. System w niespójnym stanie.
10:15 UTC - tymczasowe mitygacje
Część wewnętrznych serwisów wraca do życia. Narzędzia inżynierskie działają. Mogą iść dalej.
11:25 UTC - DNS naprawiony
Ręczna interwencja. Wszystkie informacje DNS przywrócone. Global Tables zaczynają nadrabiać opóźnienia replikacji.
Cache DNS wygasa stopniowo - między 11:25 a 11:40 klienci znowu mogą łączyć się z DynamoDB.
I tutaj już wstawałem po kawę po dobrze zrobionej robocie... ale to był dopiero pierwszy akt. Teraz zaczyna się prawdziwy chaos.
DropletWorkflow Manager - congestive collapse
DWFM zarządza serwerami fizycznymi (droplets), które hostują instancje EC2. Każdy DWFM utrzymuje "lease" z każdym dropletem pod swoją kontrolą - sprawdza jego stan co kilka minut.
Jak sprawdza? Przez DynamoDB.
Od 7:48 do 11:24 UTC te sprawdzenia przestały działać. Lease'y zaczynają wygasać. Droplet bez aktywnej lease? Nie jest kandydatem do nowych uruchomień EC2.
11:25 UTC - DynamoDB wraca. DWFM zaczyna odnawiać lease'y ze wszystkimi dropletami w regionie.
Problem? Jest ich TYLE, że praca zajmuje dłużej niż timeout lease'a.
DWFM wchodzi w congestive collapse - klasyczny problem systemów rozproszonych. Kolejka rośnie szybciej niż system jest w stanie ją obsłużyć. Lease'y wygasają zanim zostaną odnowione. Nowa praca jest dodawana do kolejki. System nie robi postępów.
Nie ma ustalonej procedury na ten scenariusz. Inżynierowie ostrożnie eksperymentują.
13:14 UTC - decyzja: throttling przychodzących requestów (stałem w tej kolejce z moimi Fargate) + selektywne restarty hostów DWFM. Czyszczenie kolejek. Redukcja czasu przetwarzania.
14:28 UTC - wszystkie lease'y odnowione. Nowe instancje EC2 zaczynają się uruchamiać.
Ale nadal dużo requestów dostaje "request limit exceeded" przez wprowadzony throttling.
Network Manager - 6 godzin backlogu
Gdy instancja EC2 się uruchamia, Network Manager musi rozpropagować jej konfigurację sieciową - VPC, routing, internet gateway. Te propagacje były opóźnione przez problemy z DWFM. Ogromny backlog się nazbierał.
15:21 UTC - Network Manager zaczyna się dławić latencją. Nowe instancje uruchamiają się, ale nie mają łączności sieciowej.
19:36 UTC - czasy propagacji wracają do normy.
22:50 UTC - wszystkie throttle'y usunięte. Pełne przywrócenie EC2.
Network Load Balancer - fail open at scale
Opóźnienia w propagacji stanu sieciowego spowodowały, że health checki NLB zaczęły failować. Węzły uznawane za niezdrowe były usuwane z serwisu.
Problem nie był w failowaniu. Problem był w powrocie.
Gdy wreszcie stan sieciowy dotarł i węzły stały się zdrowe, wszystkie wróciły do serwisu JEDNOCZEŚNIE.
AWS ma mechanizm "velocity control" - stopniowe wprowadzanie węzłów do load balancera. Ale ten mechanizm nie zadziałał przy tej skali jednoczesnego przywracania węzłów po problemach sieciowych (a nie po restarcie).
Część NLB dostała przeciążenie ruchu. Zwiększone błędy połączeń dla klientów i serwisów AWS opartych na NLB - Lambda, ECS, Connect, STS.
KONIEC! (jakby się tutaj dało kolorować to bym zrobił na czerwono)
Co AWS planuje zmienić?
Post mortem wymienia:
- Fix race condition w DNS (dodanie walidacji czy plan nie został już usunięty zanim zostanie aplikowany)
- Velocity control dla NLB przy masowych powrotach węzłów
- Nowy suite testów skalowania dla DWFM recovery workflows
- Queue-aware rate limiting żeby zapobiec collapse pod obciążeniem
- Szersze audyty resilience przez zależności między serwisami
Aktualnie automatyka DNS w DynamoDB wyłączona globalnie do czasu zweryfikowania poprawek.
Co AWS NIE planuje zmienić?
Ani słowa o tym, że us-east-1 przestanie być sercem AWS.
Ani słowa o prawdziwej niezależności regionów.
Ani słowa o tym, że global services przestaną siedzieć w jednym regionie.
Bo to by wymagało przeprojektowania fundamentów AWS. A to kosztuje więcej niż awaria raz na kilka lat.
Race condition, które czekało latami
To nie był nowy kod. To nie była nowa funkcjonalność. To była latent defect - ukryty defekt w systemie, który działał latami i czekał na idealny timing.
Wymagał:
- Enactora A z nietypowo dużymi opóźnieniami
- Enactora B aplikującego nowszy plan i kończącego dokładnie wtedy, gdy A dociera do kluczowego endpointu
- Procesu czyszczenia uruchamianego dokładnie wtedy, gdy stary plan został właśnie zaaplikowany
Prawdopodobieństwo? Mikroskopijne. Ale przy skali AWS - tylko kwestia czasu.
Dlaczego to się stało?
Bo sprawdzenie "czy plan nowszy" było na początku procesu, a nie przy każdej aktualizacji endpointu.
Bo proces czyszczenia nie sprawdzał, czy plan jest aktywny, tylko czy jest "znacznie starszy".
Bo system zakładał, że Enactor zawsze kończy w rozsądnym czasie.
To nie jest brak kompetencji inżynierów AWS. To jest właściwość złożonych systemów rozproszonych - mają zachowania, których nie da się przewidzieć bez rzeczywistego doświadczenia.
Cała infrastruktura AWS opiera się na DynamoDB. DynamoDB opiera się na DNS. DNS oparł się na race condition, który wymagał perfekcyjnego timingu.
I gdy ten timing się złożył, pół internetu przestało działać przez 16 godzin.
Pytanie nie brzmi "czy to się powtórzy".
Pytanie brzmi: ile innych race conditions czeka na swój moment w infrastrukturze, od której zależy codzienne funkcjonowanie milionów ludzi?
Jak chcecie to samo ale po technicznemu to: https://aws.amazon.com/message/101925/
🕸️ Na końcu sieci
Kohler Dekoda: Smart Toilet z kamerą za $599
Kohler wypuścił kamerę montowaną do toalety, która analizuje twoje kupy pod kątem zdrowia jelit, wykrywa krew i ocenia nawodnienie. Za 600 dolarów możesz mieć urządzenie IoT z baterią USB-C, WiFi i wieloma profilami użytkowników (z czytnikiem linii papilarnych!), które śledzi konsystencję, kształt i częstotliwość twoich wypróżnień.
Apple ostrzega developera exploitów, że został celem ataku
Jay Gibson, developer iOS zero-days dla Trenchant (L3Harris), dostał od Apple powiadomienie o ataku mercenary spyware na jego iPhone. Gibson wierzy, że to zemsta za to, że firma zrobiła z niego kozła ofiarnego za leak narzędzi Chrome, do których nawet nie miał dostępu - był w zespole iOS.
BBC reporter dostał ofertę od gangu ransomware
Dziennikarz BBC Joe Tidy został zaproszony przez grupę Medusa do zhakowania własnego pracodawcy za 15-25% okupu (potencjalnie dziesiątki milionów). Gdy zwlekał, hakerzy zastosowali MFA bombing - zalali jego telefon nonstop prośbami o uwierzytelnienie, próbując go zmęczyć do kliknięcia "zaakceptuj".
🚽Zamknięcie klapy
Czasem zastanawiam się, czy bardziej absurdalne jest to, że AWS postawił całą infrastrukturę na race condition, czy to, że ktoś uznał iż musimy mieć IoT monitorujące nasze kupy.
Ale pewnie oba problemy rozwiążemy tym samym sposobem: poczekamy aż coś się spier... na tyle głośno, że nie da się udawać że tego nie widzimy.
Do następnego race condition, Your friend in time
Marcin Rybak
Member discussion